We present MoE-Loco, a Mixture of Experts (MoE) framework for multitask locomotion for legged robots. Our method enables a single policy to handle diverse terrains, including bars, pits, stairs, slopes, and baffles, while supporting quadrupedal and bipedal gaits. Using MoE, we mitigate the gradient conflicts that typically arise in multitask reinforcement learning, improving both training efficiency and performance. Our experiments demonstrate that different experts naturally specialize in distinct locomotion behaviors, which can be leveraged for task migration and skill composition. We further validate our approach in both simulation and real-world deployment, showcasing its robustness and adaptability.
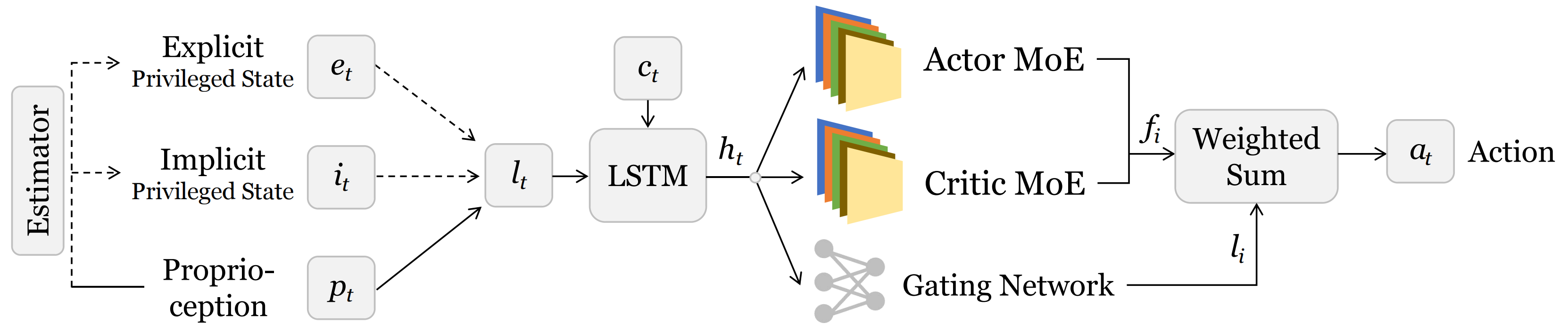
Our training primarily follows the Probability Annealing Selection (PAS) paradigm. Overall, the robot utilizes both previleged and proprioceptive information in the first stage, and gradually transitions to proprioceptive information only in the second stage by probablistic annealing. The key design is that we incorporate a Mixture of Experts (MoE) structure to handle the multi-task reinforcement learning problem.
\begin{equation} \hat{\boldsymbol{g}_{i}} = \text{softmax} (g(\boldsymbol{h}_t))[i] \end{equation} \begin{equation} \boldsymbol{a}_t = \sum_{i = 1}^{N}\hat{\boldsymbol{g}_{i}}\cdot f_{i}(\boldsymbol{h}_t) \end{equation}
The MoE architecture facilitates the coordination of similar task skills while minimizing conflicts between heterogeneous tasks by dynamically routing tasks to appropriate experts. This automatic routing enables specialization, improving both efficiency and task performance. Additionally, we incorporate MoE into the critic network to better capture diverse task reward structures.
With the automatic decomposition of expert skills, we can recombine them with adjustable weights to synthesize new skills and gaits. Formally, we leverage pretrained experts and modify the gating weights as follows:
\[ \hat{\boldsymbol{g}_{i}} = w[i] \cdot \text{softmax} (g(\boldsymbol{h}_t))[i], \]
where \( w[i] \) can be manually defined or dynamically adjusted by a neural network. This formulation enables controlled skill blending, allowing the robot to adapt and generalize to novel locomotion patterns. The skill composition results from the automatic skill decomposition and interpretability inherent in the MoE architecture. In contrast, a standard neural network would function as a black box, lacking such interpretable skill decomposition.
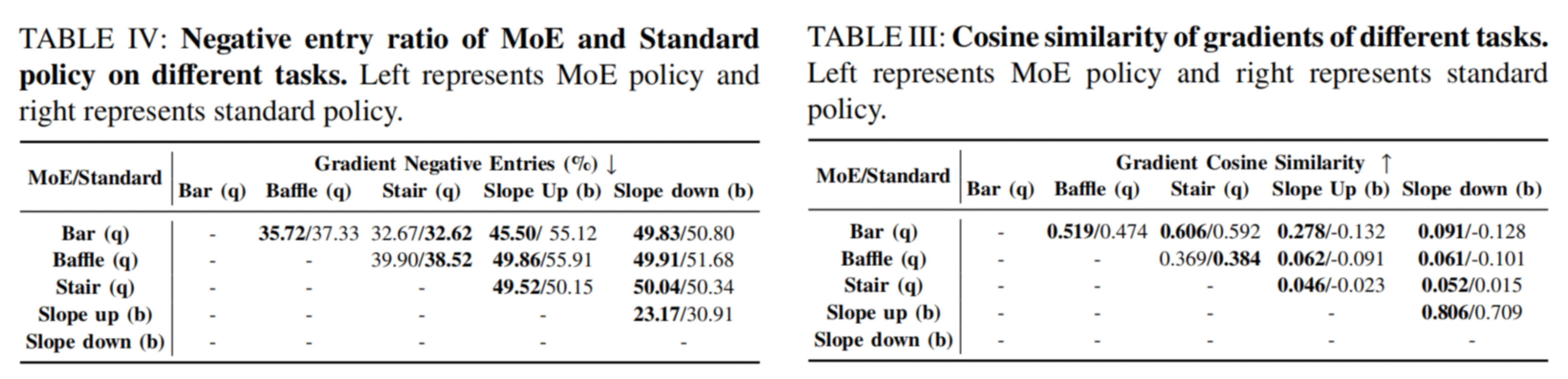
The MoE policy significantly reduces gradient conflict between bipedal and quadrupedal tasks. It also minimizes gradient conflict even between quadrupedal tasks that require fundamentally different skills, such as quadrupedal bar crossing and quadrupedal baffle crawling.
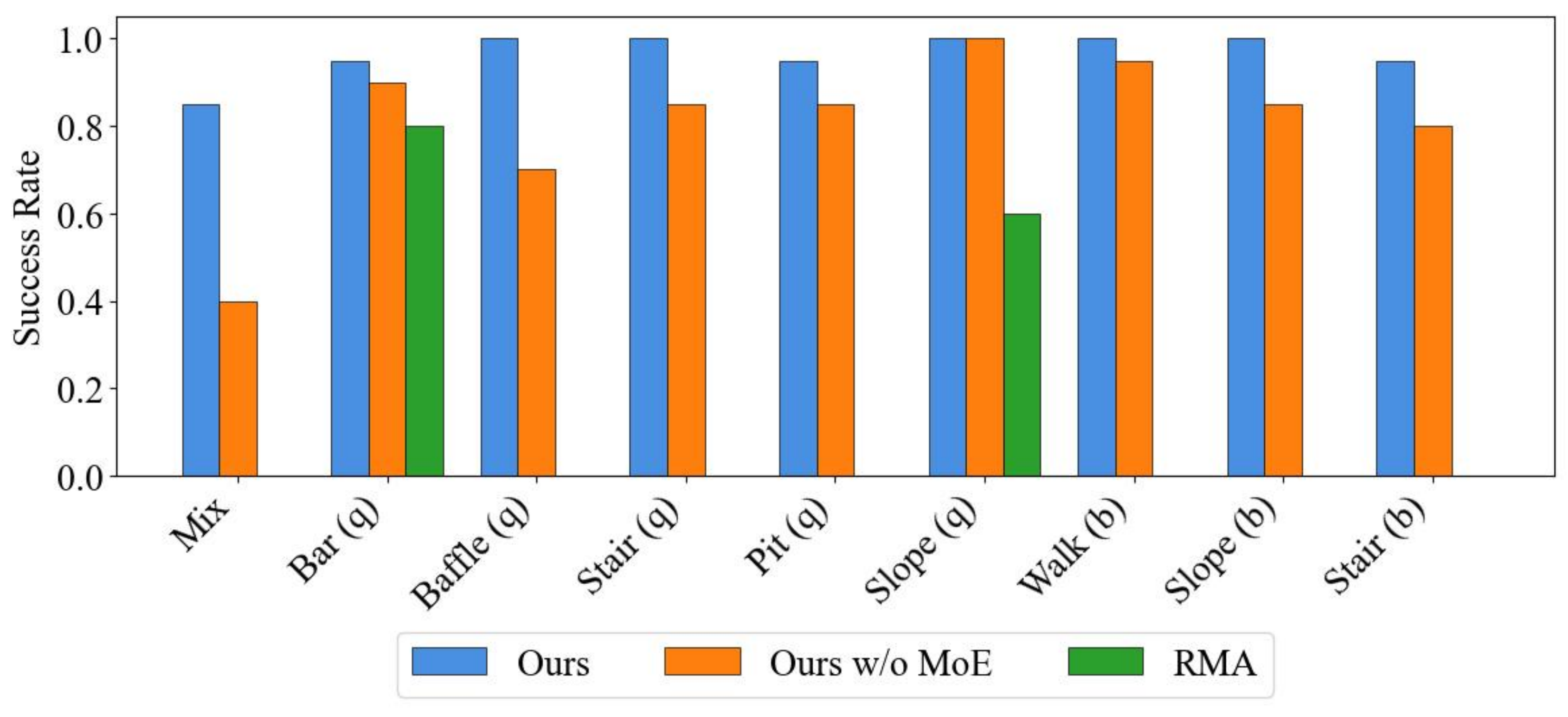
We conducted real-world experiments over multiple terrains and gaits: 1. Bar (Quad), 2. Pit (Quad), 3. Baffle (Quad), 4. Stair (Quad), 5. Slope (Quad), 6. Stand up (Bip), 7. Walk (Bip), 8. Slope (Bip), 9. Stair (Bip).

We deploy our MoE policy zero-shotly on real robots and conduct real world experiments. We test mix terrain that contains all challenging tasks, as well as each separated terrains.
We examined the expert usage in different tasks. We plot the mean weight of different experts across various tasks. It is evident that the distribution of gating weights varies significantly from task to task, demonstrating the expertise and differentiation of various experts.

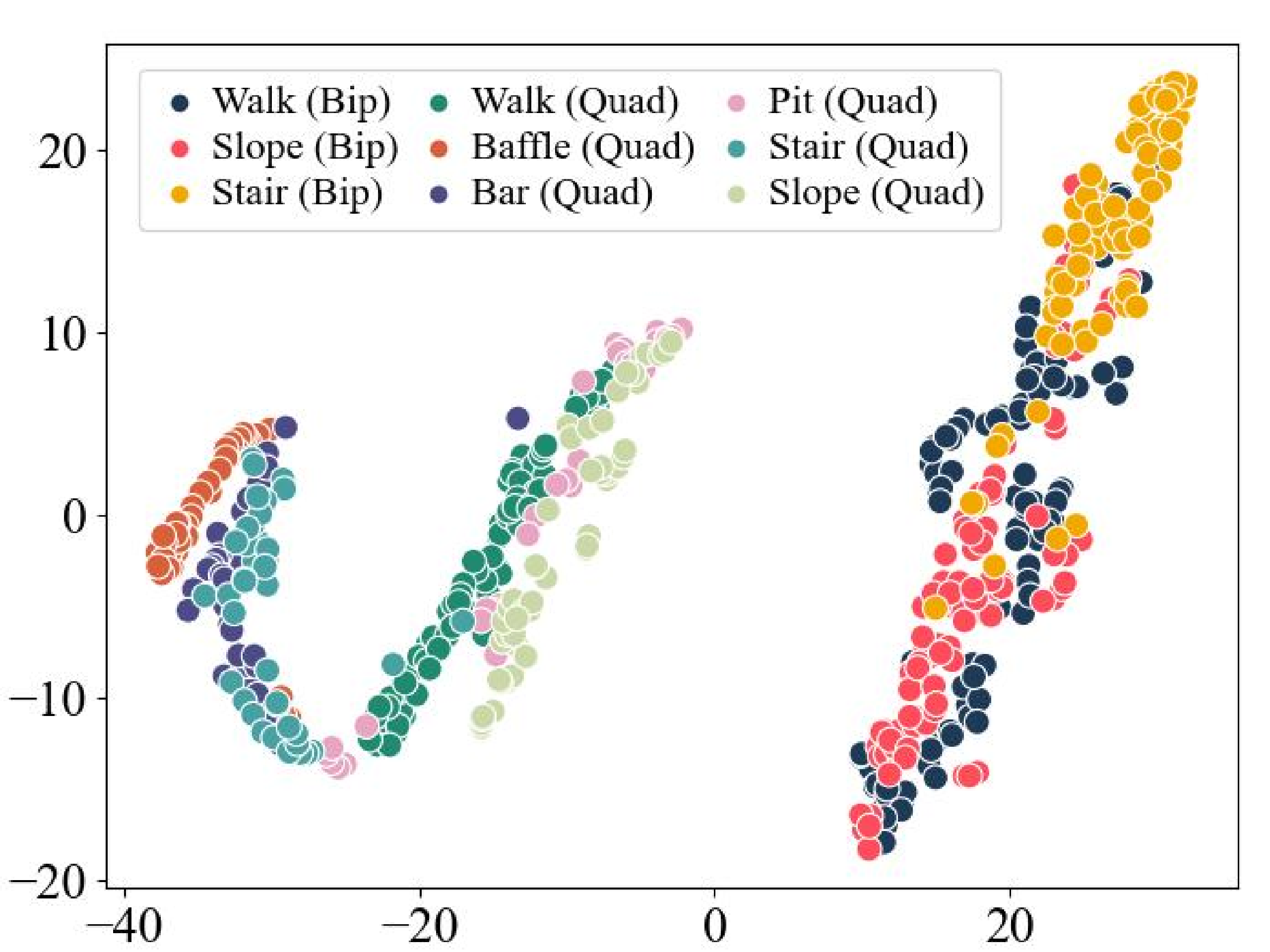
To further analyze the composition of different experts across various tasks, we use t-SNE to visualize the output of the gating network for different tasks (i.e., the weight of each expert). As shown below, the bipedal and quadrupedal tasks form distinct clusters.
We discovered that one expert specializes in balancing, which helps lift the robot's body but limits its agility. Another expert is responsible for lifting one of the front legs to perform crossing tasks, enabling the robot to execute basic movement skills. By selecting the balancing expert and the crossing expert, we are able to zero-shot transfer to a new dribbling pattern. The new dribbling gait allows the robot to walk effectively while periodically using one of its front legs to kick the ball.

We conduct an adaptation learning experiment to demonstrate how our pretrained experts can be recomposed and adapted to new tasks. In this experiment, we design the robot to walk on three feet.

We constructed a benchmark for quadrupedal robot locomotion across different tasks. Our benchmark consists of a 5m times 100m runway with various obstacles evenly distributed along the path.
@article{huang2025moe,
title={MoE-Loco: Mixture of Experts for Multitask Locomotion},
author={Huang, Runhan and Zhu, Shaoting and Du, Yilun and Zhao, Hang},
journal={arXiv preprint arXiv:2503.08564},
year={2025}
}